
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- jupyter
- Skip Connectioin
- DL
- Residual Connection
- AI
- Vanilla RNN
- sigmoid
- Generative
- Linear
- classification
- RNN
- Regression
- Manager
- version
- ResNet
- GCN
- Optimizer
- Gated Skip Connection
- python
- Inception Module
- vim-plug
- Bottleneck Layer
- Inception V1
- cnn
- Skip Connection
- GoogLeNet
- DCGAN
- virtualenv
- Peephole Connection
- iTerm2
- Today
- Total
IT Repository
(1) Basic of RNN - Sequence Data 본문
What is Sequence Data?¶
이번에는 순서가 있는 데이터에 대해서 생각해보겠습니다.
(1)
예를 들어, 일년의 온도 변화와 같은 데이터는 시간의 순서가 있는 데이터입니다.
오늘의 온도는 어제의 상태에서 변화한 값이고, 이를 더 큰 범위에서 생각해보면 오늘의 온도는 그 전의 모든 결과를 반영하는 값입니다.
(2)
이번에는 이전의 온도와 유사한 관점에서 글자 혹은 문장을 생각해보겠습니다.
"나는 지금 공부를" 이라는 단어를 순서대로 들었다고 가정했을때에 우리는 "한다" 혹은 "합니다" 등을 예측할 수 있습니다.
오늘의 온도가 그 전의 모든 온도 결과값을 반영하면서 나온 결과인 것과 같이 "한다" 혹은 "합니다" 역시 "나는 지금 공부를" 을 반영한 결과라고 생각할 수 있습니다.
이를 글자 단위로 생각해도 동일합니다.
이와 같이 순서가 있는 데이터를 우리는 시퀀스(Sequence)라고 부릅니다.
아래는 이와 같은 시퀀스 데이터에 대한 문제입니다.
(우리가 RNN으로 해결해야 할 문제의 예시입니다.)
- Automatically generate caption with the given images (Sequence of words)
- Predict whether a company would be bankrupted (Sequence of balance)
- Translate one sentence into another language (Sequence of words)
- Classify whether the word is owns' name or not (Sequence of characters)
Classical Approach for Time Series Analysis¶
아래는 이러한 시퀀스 데이터를 분석하는 전통적인 방법입니다.
저 역시도 아래의 내용을 전부다 알지는 못하며 이런게 있구나 정도만 확인하고 넘어가시면 될 것 같습니다.
중요한 것은 아래의 방법들은 Feature를 매뉴얼하게 Selection 혹은 Extraction 해야 한다는 것입니다.
딥러닝을 사용한다면 매뉴얼한 과정없이, NN기반으로 컴퓨터가 유용한 Feature를 추출하고 Regression을 하게 됩니다.
- Time domain anaysis
- width, step, height or signal을 확인하여 분석
- Frequency domain analysis
- Fourier analysis
- wavelets 등을 통해 특정 파형이 있는지 분석
- Nearest neighbors analysis
- Dynamic TIme Warping: sequential data끼리 어떻게 similarity를 발견할 것인가에 대한 방법 중 하나
- Probabilistic model
- 주어진 시퀀스에 대해서 확률적으로 다음에 나올 값을 확률적으로 모델링하는 이론 (ex.Language modeling)
- (S)AR(I)MA(X) models
- Autocorrelation inside of time series: 통계적으로 시계열 내에 autocorrelation 이라는 특성이 있는지 없는지를 확인
- Decomposition
- Time series = trend part + seasonal part + residuals
- 원래의 time series에서 각 part들을 분해하는 분석방법
- Nonlinear dynamics
- Differential Equation (ordinary, partial, stochastic)
- Machine learning
- Use ML model with hand-made features
- 위의 방법들을 통해 featurize 하고, 도출되는 feature 들을 통해 regression
Sequential Data with MLP and CNN¶
이제 이 시퀀스 데이터를 딥러닝으로 다루려고 합니다.
우리가 생각해볼 수 있는 구조는 MLP 혹은 CNN 구조일 것입니다.
(1)
먼저 MLP를 생각해보겠습니다.
MLP로 시퀀스를 다룬다면 인풋 텐서를 리사이징해서 압축하거나 혹은 Flattening해서 다뤄야 겠네요.
이 압축과 Flattening은 이미지를 다룰 때에도 Spatial Information을 MLP가 고려할 수 없었던 것과 같이
시퀀스 데이터도 역시 순서를 고려하지 못하게 됩니다.
(동일한 문자가 주어졌을 때에 순서가 바뀌는 것만으로도 여러가지 단어가 나옵니다.
MLP는 순서를 고려하지 않으니 이러한 단어를 모두 동일한 것으로 보겠죠. 예시가 생각이 안나서 죄송합니다;)
(2)
그러면 이번에는 CNN을 생각해보겠습니다.
결론부터 말씀드리면 CNN에서 한번 언급했던 것과 같이 CNN은 이러한 시퀀스 데이터를 다룰 수 있습니다.
단, 기존의 2D 데이터가 아닌 1D 데이터, 특히 텍스트를 다루기 위해 1D Convolution Layer를 사용합니다.
레이어가 작동하는 방식은 이전과 동일하게 필터를 슬라이딩하고 Activation하고 Pooling을 수행합니다.
데이터의 Dimension만 변했을뿐입니다.
이러한 Conv 1D의 각 층의 역할은 아래와 같습니다.
- Conv : 필터를 슬라이딩하면서 유용한 Feature를 추출
- Pool : 어떤 Feature를 주목해야 하는지에 대한 Attension 결정
- FC : Feature map과 아웃풋을 매핑
이미 tensorflow나 torch에도 Conv1D 레이어가 구현되어 있고 개념 역시 동일하니 Conv 1D에 대해 공부할만한 사이트를 소개하고 넘어가겠습니다.
(Recommend to read: https://machinelearningmastery.com/how-to-develop-convolutional-neural-networks-for-multi-step-time-series-forecasting/)
Types of Task Dealing with Sequential Data¶
지금까지 고전적인 방식으로 시퀀스 데이터를 다루는 것과 우리가 지금까지 학습했던 내용으로 시퀀스 데이터를 다루는 것을 알아보았습니다.
이제부터는 새로운 구조인 RNN을 학습하기 위해 시퀀스 데이터로 우리가 다룰 수 있는 작업들의 종류를 알아보겠습니다.
(즉, RNN으로 해결할 수 있는 문제들이 이거구나 라고 생각해주시면 되겠습니다.)
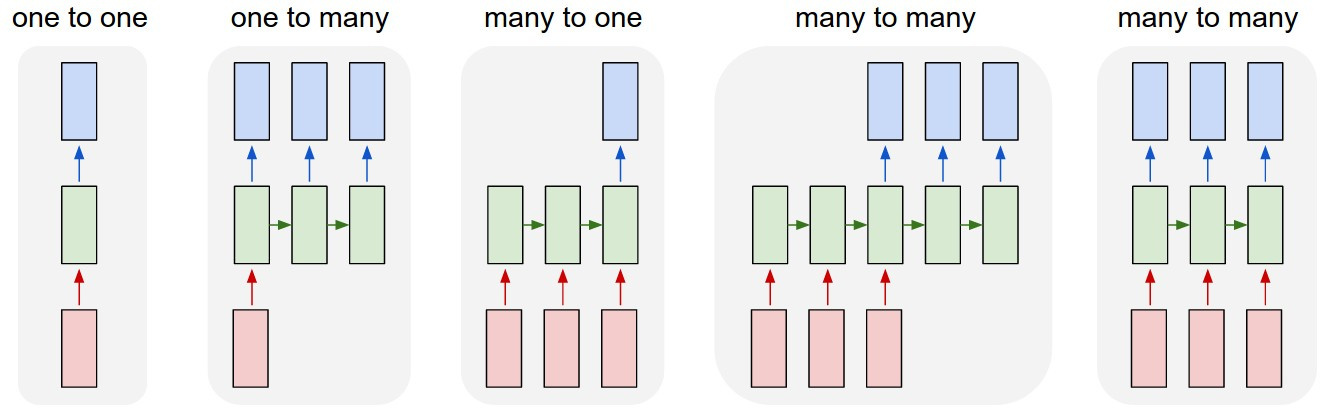
1. One to One
이러한 구조는 사실 기본적인 구조의 MLP 와 CNN 구조로써 많이 보았습니다.
하나만 있는 것은 순서도 없으므로 당연히 시퀀스 데이터라고 볼 수 없습니다.
2. One to Many
하나의 벡터를 시퀀스에 매핑하는 경우입니다.
Image Caption : CNN을 통해 나온 하나의 벡터를 각각 단어에 매핑합니다.
3. Many to One
시퀀스를 입력해서 하나의 벡터를 출력받는 경우입니다.
Bankrupt Prediction : 주가의 흐름을 시퀀스로 입력받아 하나의 벡터에 매핑한 후에 도산여부를 분류 합니다.
4. Many to Many (A Type)
시퀀스를 입력받아 이를 변환한 다른 시퀀스를 출력하는 경우입니다.
Translation : 글자의 시퀀스인 "Apple"를 입력받아 이를 고차원의 Feature 벡터로 만든 후에 다시 "사과" 라는 글자의 시퀀스로 변환합니다.
5. Many to Many (B Type)
시퀀스를 타입스텝마다 각각 하나의 출력을 갖게 하는 경우입니다.
Pos Tagging: 단어의 시퀀스인 문장을 입력받아 이를 매 단어(타임스텝)마다 단어의 품사를 예측합니다.
Dimension of Sequence Data¶
CNN에서 프레임워크를 사용해서 이미지를 처리하기 위해 데이터의 차원을 맞추었듯이
시퀀스 데이터 역시 마찬가지 입니다.
(Samples, Timesteps, Features) : Tensorflow, Pytorch
(Timesteps, Samples, Features) : PyTorch (옵션을 지정한 경우)
다행히 이번에는 두 프레임워크 모두 동일하게 사용할 수 있습니다.
다만, PyTorch에서는 코딩의 편의성을 위해서
Sample 축과 Timestep 축을 Transpose하는 옵션을 활용할 수 있다는 것을 기억하시면 되겠네요.
'RNN > Study' 카테고리의 다른 글
| (4) GRU (0) | 2020.01.17 |
|---|---|
| (3) LSTM (0) | 2020.01.17 |
| (2) Basic of RNN - Vanilla RNN (0) | 2020.01.16 |
| (0) Overview of RNN (0) | 2020.01.14 |