
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- DL
- classification
- Peephole Connection
- Skip Connection
- Generative
- Inception V1
- cnn
- Gated Skip Connection
- Linear
- Inception Module
- Skip Connectioin
- GCN
- Manager
- vim-plug
- python
- DCGAN
- AI
- Vanilla RNN
- jupyter
- version
- virtualenv
- GoogLeNet
- sigmoid
- Bottleneck Layer
- ResNet
- Residual Connection
- Regression
- iTerm2
- Optimizer
- RNN
- Today
- Total
IT Repository
(6) GoogLeNet (Inception Module & BottleNeck Layer) 본문
GoogLeNet (2014)¶
VGGNet에서 언급하였듯이 GoogLeNet은 2014년도 ILSVRC의 우승 모델입니다.
Inception V1이라고 불리며 한번쯤은 들어보았을 만한 Inception V2, V3 시리즈의 초기 버젼입니다.
22개의 레이어를 사용하였으며 GoogLeNet을 시작으로 단순한 CNN 구조에서 좀 더 복잡한 구조의 CNN 모델이 탄생했습니다.
먼저 GoogLeNet의 구조를 가볍게 구경해보겠습니다.

이렇게 복잡하고 깊은 층으로 네트워크를 구성하면 우리가 학습하였듯이 파라미터 수의 증가로 인한 Overfitting과 연산량의 문제가 발생할 수 있습니다.
하지만 GoogLeNet은 놀랍게도 AlexNet 보다도 적은 파라미터의 수와 적은 연산량을 보입니다. (아래 사진 참고)
VGGNet과 비교해보아도 138M vs 5M으로 비교가 되지 않을 정도입니다.
즉, GoogLeNet은 더 깊은 망을 사용하면서도 파라미터의 수를 획기적인 방법을 사용했습니다.

GoogLeNet의 특징¶
이러한 GoogLeNet은 2가지의 새로운 개념을 사용하고 있습니다.
- Inception Module
- Bottleneck Layer
- No FC Layers
Inception Module¶

Inception Module은 위의 그림과 같이 하나의 Filter size가 아닌 여러 종류의 Filter size를 적용하고자 하였습니다. (Multiple receptive field)
위와 같이 동일한 레벨으로 레이어들을 구성하면 여러 Receptive Field를 확보하면서도 네트워크가 깊어짐으로써 생기는 문제점을 해소할 수 있습니다. (Not deeper, but wider) 상세 순서를 설명하면 아래와 같습니다.
- Input Tensor를 여러 Filter size의 Conv 층에 통과시키고, Pooling 층에도 통과시킴
- 각 Output을 Concatenation
Problem of Naive Inception Module
그러나 이러한 기본적인 Inception Module은 한 가지 문제점이 있었습니다.
pooling층은 height와 width를 변화시키기 위함이지 depth를 변화시키지 않습니다.
따라서 Inception Module의 마지막에서 concatenation을 한다면 depth가 점점 더 두꺼워지게 됩니다.
(최소한 input tensor보다는 더 큰 depth를 갖게 되기 때문입니다.)
Depth가 두꺼워지는 문제는 결국 층이 깊어질 수록 computation efficiency가 떨어지는 결과를 초래하게 됩니다.
Bottleneck Layer¶
GoogLeNet은 위의 Naive Inception Module의 문제점을 해결하기 위해 Tensor의 Depth를 줄이기 위해 Bottleneck Layer를 사용합니다.
즉, Dimension reduction을 위한 층을 두는 것입니다.
방법은 간단합니다. 1x1 Conv층을 사용하여 Depth를 줄이는 것입니다.
(1x1 이상의 filter size를 사용하여도 depth를 줄일 수 있으나,
computation amount는 그만큼 증가하게 되므로 Bottleneck layer에서는 depth만을 줄이고 다른 층에서 conv operation을 수행함)
이것이 GoogLeNet이 22개의 레이어를 사용하는 깊은 네트워크를 구성하면서도 연산량을 줄일수 있는 방법이었습니다.
Inception Module with Bottleneck Layer¶

Bottleneck Layer를 적용한 Inception Module을 살펴보면 아래와 같습니다.
- input tensor를 1x1 conv 층에 통과시킴으로써 차원을 축소함 (Dimensionality Reduction)
- 차원이 축소된 tensor를 여러 filter size의 conv 층에 통과시키고 (Cascade 방식), input tensor는 pooling층에 통과시킴
- 각 output을 concatenation
여기서 알아두어야 하는 것은 1x1 conv 층을 통해 차원을 축소하고
Cascade 방식으로 여러 Receptive field를 확보한다는 것입니다.
만약 차원 축소를 하지 않는다면 GoogLeNet과 같이 깊은 네트워크의 경우 수많은 연산량이 발생하게 될 것입니다.
GoogLeNet은 이를 1x1 conv를 사용한 차원 축소를 통해 input tensor의 차원을 줄이고
그 후에 3x3, 5x5 conv 층에 통과시킴으로써 연산량을 줄입니다.
알아두어야 할 것은 pooling 층은 pooling을 한 이후에 차원을 축소한다는 것입니다.
이는 어찌되었든 차원 축소로 생기는 정보 손실을 고려하여,
먼저 강한 stimulus를 추출하고 그를 기준으로 유용한 feature를 추출하는 것이 반대 상황보다 유리하다고 판단했기 때문으로 생각됩니다.
No FC Layers¶
이제 다시한번 GoogLeNet의 구조를 보겠습니다.
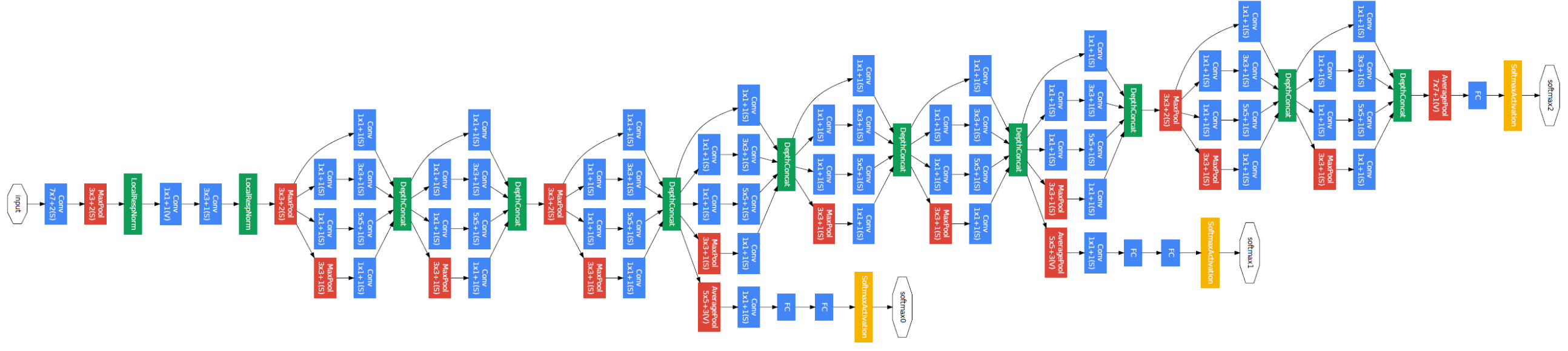
최종적으로 사용되어 Class의 수만큼 분류하기 위한 1개의 FC 레이어만 사용되고 있는 것을 알 수 있습니다.
GoogLeNet을 소개한 논문에서는 이를 통해 FC Layer에서 과도한 파라미터가 발생하는 것을 해소했기에 FC Layer가 없다고 설명합니다.
추가적으로 중간에 하나씩 곁가지가 나와있는 것은 Gradient Vanishing을 해소하기 위한 테크닉입니다.
중간중간에 저런 브랜치에서 Loss를 구해서 Backpropagation을 하면 깊은 층에서 Gradient가 사라지는 문제를 어느정도 해결할 수 있습니다.
상대적으로 더 가까운 곳부터 Chain Rule을 통해 Backward 하기 때문입니다.
'CNN > Study' 카테고리의 다른 글
| (8) GCN - What is Graph (0) | 2020.01.17 |
|---|---|
| (7) ResNet (Residual Connection) (16) | 2020.01.14 |
| (5) VGGNet (Small Filters with Deeper Networks) (0) | 2020.01.14 |
| (4) AlexNet (0) | 2020.01.14 |
| (3) Basic of CNN - Structure of CNN (4) | 2020.01.14 |
